

Introduction
I have set up Kubernetes (K8s) platforms for a couple of large enterprises that already had a lot of infrastructure as code (IaC) managed by dedicated teams. I am a big fan of IaC, and there are good tools out there, e.g., Terraform, Pulumi, ARM (if you are only using Azure), and now Bicep for Azure, etc. However, the question inevitably comes up: “Since IaC is so good and it has support for creating K8s objects as well, why not use it for managing the K8s state? Or at least make deployments through IaC.”?
Where does the IaC start and end, and when does the configuration as code start and end?
The IaC and GitOps balance
I think there are better tools out there for keeping the K8s state stored and doing deployment than IaC. The GitOps implementation Flux is one such tool. For an introduction to GitOps, secret management, and branching strategies please look at my post: GitOps and branching strategies – fredrkl.
In my mind, the IaC starts on ground zero, creates networks, resource groups, and in general, the smallest amount possible in terms of K8s to bootstrap the GitOps components and kick of the reconciliation. GitOps is good at reconciling K8s objects from repos, applying Kustomize, and possible Helm transformations. Why this minimal IaC approach? For a couple of reasons. We eliminate all the complicated IaC state management and reduce it to firing off some Azure CLI commands when using Azure.
Additionally, GitOps has no overhead on the native K8s YAML. It is just plain YAML stored in Git. GitOps also give us a lot of freedom on how we want to structure our platform and applications running on it in terms of Git repos. We will later see an example of using different repos to synchronize systems, applications, and platform components using GitOps.
The reconciliation feature is an essential part of Terraform, Pulumi, or other infrastructure code tools. If the infrastructure drifts away from what you specified in the code, the tooling will rectify that. Good stuff. However, we do not need that feature with the YAML in K8s. K8s already has this feature built-in. Just store the end state you want, and K8s will try to make that a reality. Additionally, if anyone would change the YAML definitions directly in K8s, then GitOps will overwrite it with whatever is in the repo using regular syncs. No need for complicated diffing; go for reconciliation loops instead.
Example setup
There is no one way to create a GitOps setup. However, let us look at an example of how I did it in my previous project for a large insurance company here in the Nordics. Let us start with bootstrapping.
Bootstrapping
We used Azure DevOps build pipelines to run a small bash script. We added any secrets necessary for bootstrapping that could not be a part of the repo, as Azure DevOps environment secrets. The only secret necessary was the private key for the sealed secret controller.

The bash script fires off a couple of Azure CLI commands, creating the Azure Kubernetes Service (AKS). In our case, it creates the AKS in an already defined Azure Network provisioned and configured by the networking department. They managed any on-premises connections, UDRs, firewall configurations for outbound calls, etc. Once AKS is up and running, the script gets the kubectl credentials, installs the sealed secrets controller with the private key, and the Flux (fluxcd.io) v2 control components. The script then starts the bootstrapping by applying the smallest amount of Flux CRDs to pull in the YAML code from a repo called Platform Components on the environment-specific branch and kustomize directory. The Flux documentation is good and better explains the GitRepository and Kustomization CRDs than I would do here. It is important to note that we are not using branches to hold the state of different environments. Although we have a branch per environment (dev, test, and prod), we introduce changes in the dev branch and use the “regular” kustomize structure to cope with the environment-specific changes. To move changes from dev to test, we make a pull request that we fast forward. The dev K8s cluster pulls in changes from the dev branch, test K8s cluster from the test branch, and prod from the main branch.
Platform Components
Moving on to the Platform components repo. This repo consists of, not surprisingly, the platform components. Examples of platform components are Linkerd, Prometheus Operator and instances, KEDA, etc. Here is a depiction:
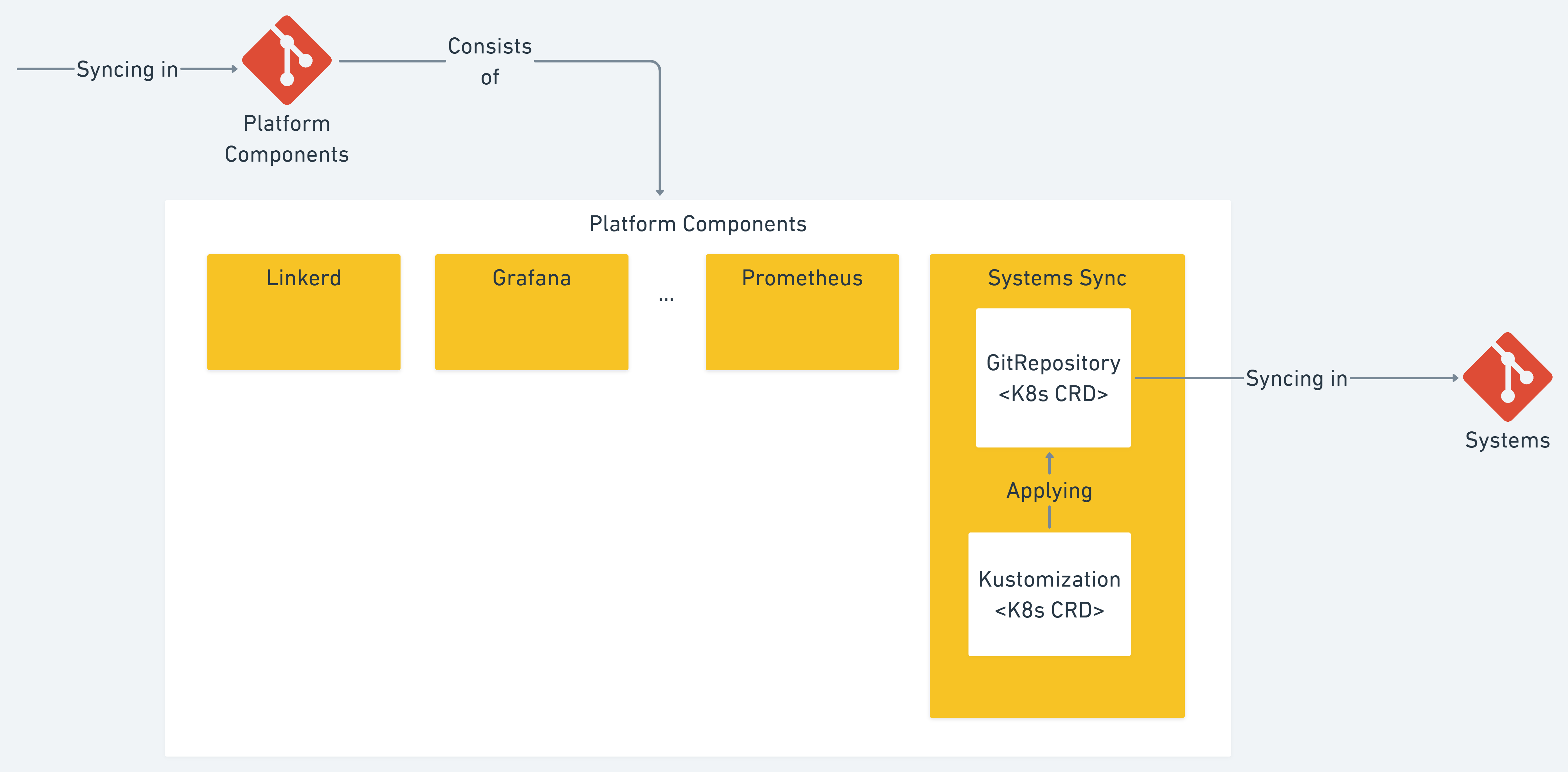
The last part that Platform Components has is the Systems Sync which configures the synchronization of the Systems.
Systems
And finally, we have the systems. We had a 1:1 relationship between an Azure DevOps Project, GitOps repo, K8s Namespace, Azure AD Group, and team. The platform team would create a repo for each team and configure the synchronization by adding it to the systems repo. The team would add all of their YAML for all their applications to the Git repo.
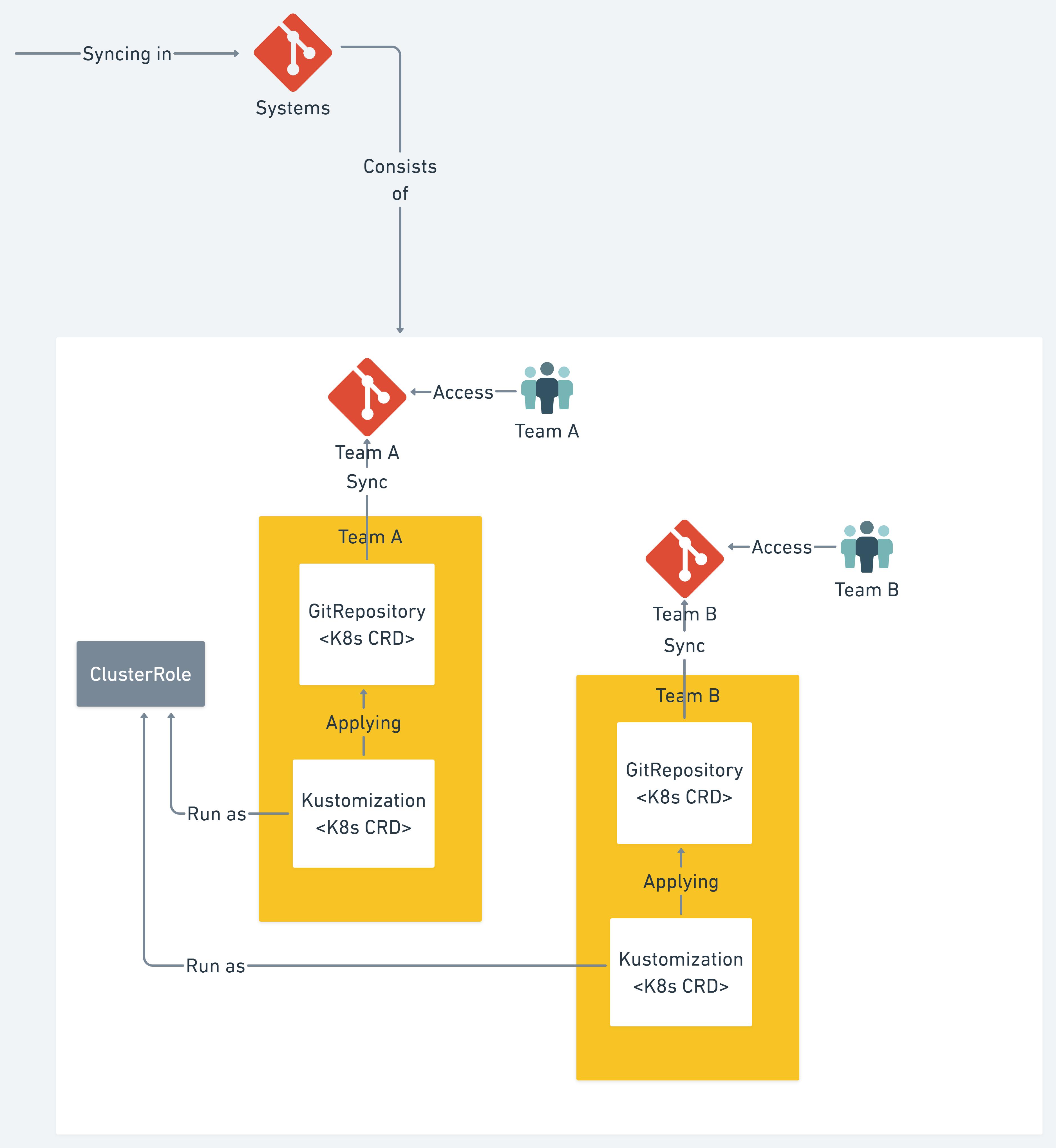
One of the many good things with Flux v2 is that the Kustomization CRDs can run as K8s Service Accounts (SAs) that we can bind to Roles or ClusterRoles. Why is that good? Well, the K8s admins control the ClusterRole definition. We have complete control of what K8s objects the teams can and can not create. Do they make a K8s Service of type Load Balancer by mistake? Fear not. They will get notifications from the Kustomize controller that it does not have the proper permissions to create the object. Flux v2 also has support for sending those notifications to Slack and MS Teams solutions. We added an MS Teams channel for each System and sent any Kustomizations messages there. The team was therefore notified about the error and could rectify it.
Azure Service Operator
An argument that often comes, or maybe not an argument but a question, is what do you do with secrets or configuration that you get from the creation of other Azure resources, e.g., database connection strings? What we did was to add those secrets as sealed secrets keeping them in the repo together with the rest of the YAML code. However, wouldn't it be better if those secrets got added as secrets in K8s when the resource got created. Also, why not be able to create the Azure resources that the different systems need using GitOps as well? That is, I think, the reason behind the | Azure Service Operator project. If you need a database for a system you simply add a YAML definition in the repo and have Flux sync it in before the Service Operator provisions create one for you. This approach is a contention on K8s being the central component in your setup. Together with a Kafka cluster, K8s is usually in the center of the large enterprise's application's platform.
Disaster recovery
A very nice side effect of keeping the entire state in a set of repos is the ease of disaster recovery. Instead of running a large set of release pipelines wherever we have a new cluster in a disaster recovery scenario, we can just lean back and watch all of the repos with all of the applications start syncing in. At the insurance company, we actually stopped making upgrades of K8s in the portal. Instead, we deleted the cluster, updates the bootstrapping script with the new K8s version, and recreated it. We were able to go from zero to hero in about 25min. the majority of that time was spent waiting for the VMs booting up and the images being downloaded.
Summary
There is a balance between what to keep as IaC and what to keep as configuration outside of it. In this blog post we have seen an example of a minimal approach to IaC and instead, have the state and manage the deployment with Flux - a GitOps implementation. We have seen how we can separate the different responsibilities of K8s admins, networks admins, architects, and teams developers by using different Git repos with GitOps. With the GitOps approach, we are able to make changes to the systems configurations completely repeated from the applications that make up it. We are also much more resilient towards disasters.